Semiconductor supply chain is booming: The supply deficit leads to elevated prices and gross margins across the entire AI semiconductor supply chain. We identify the stocks that benefit from supply/demand imbalance in 2026-2027.
AI chip complexity increases: NVIDIA’s transition to the Rubin platform, with 60% more transistors and 50% larger HBM4 capacity triggers fierce competition for TSMC’s 3nm capacity and HBM4 memory supply.
TSMC’s Absolute Capacity is exhausted: The simultaneous migration of NVIDIA, AMD, and custom hyperscaler ASICs to the 3nm standard has completely absorbed TSMC’s fabrication and CoWoS packaging capacity through 2026, driving prices and margins up.
Bottlenecks in Memory and down the supply chain: The HBM market is in a deep deficit, allowing the leading 3 producers to dictate premium pricing and drive gross margins to record levels. The physical complexity of new architecture has severely extended diagnostic times, creating testing and rack assembly bottleneck.
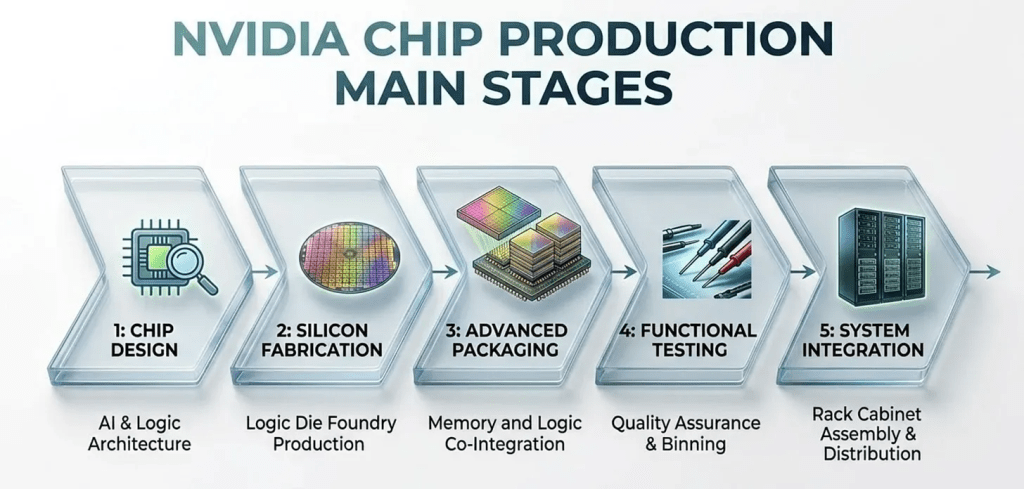
Stages of chip design and value chain
At CES 2026, NVIDIA unveiled the Vera Rubin platform – the next generation of its chips. Compared to previous Blackwell architecture, the focus shifts to inference efficiency and cost reduction. Vera Rubin is engineered to enable efficient deploying trillion-parameter Mixture-of-Experts (MoE) models and rapid adoption of Agentic AI. NVIDIA claims, the platform achieves a 10x reduction in inference token costs and a 35x increase in inference throughput per megawatt compared to Blackwell. This leap is facilitated by a more complex, highly integrated silicon stack: the Rubin GPU is paired with the Vera CPU—NVIDIA’s first fully custom ARM-based processor—and sixth-generation HBM4 memory, providing a massive 22 TB/s of bandwidth. By integrating 72 Rubin GPUs and 36 Vera CPUs, combined with 20.7TB HBM memory and 260TB/s NVLink Bandwidth into a unified rack-scale system, NVIDIA is moving beyond discrete components toward a “POD-scale” supercomputer designed to maximize revenue opportunity per watt in the inference phase.
The value creation across the AI accelerator production lifecycle is asymmetric, reflecting the distinct capital intensity and intellectual property moats. Chip Design is made by NVIDIA itself , while the physical execution is entirely outsourced. Silicon Fabrication and Advanced Packaging represent highly defensible profit pools dominated by capital-intensive pure-play foundries, and is almost to 100% dominated by TSMC. At these stages, the critical co-integration of complex logic dies with high-bandwidth memory acts as a primary supply bottleneck and a major value driver for the manufacturer. Following strict Functional Testing and yield binning to optimize unit economics, the final stage of System Integration delegates rack cabinet assembly, thermal management, and distribution to Original Design Manufacturers (ODMs). At these stages the margins remain structurally lower and competition higher than in the upstream design and advanced packaging phases.
Rubin requires 3nm production process and relies heavily on advanced HBM4 memory chips – both are in tight supply
The transition to the Vera Rubin platform introduces a significantly more complicated system topology, shifting from discrete accelerators to a deeply integrated, multi-chip computational matrix. The technological advancement allows increased architectural complexity in the underlying hardware and silicon, notably the migration to TSMC’s 3nm process node, which allows the Rubin GPU to accommodate 336 billion transistors. By pairing these high-density compute dies with next-generation HBM4 memory and the purpose-built, Arm-based Vera CPU, the infrastructure systematically eliminates historical bandwidth bottlenecks.
Source: SLP Alpha Research
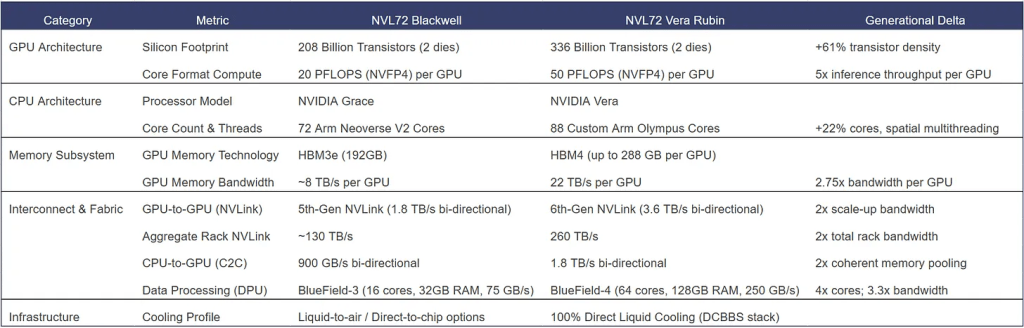
The table above compares some parameters of Blackwell based NVL72 rack and Rubin based rack. Apart of improvement in the GPU and CPU chips, there is significant increase in required memory and network chips.
TSMC – (near)monopoly for at scale 3nm production and packaging
The reliance of the NVIDIA Vera Rubin architecture on TSMC’s advanced 3nm process node creates a structurally constrained supply environment that directly benefits the foundry’s financial outlook. With hyperscalers aggressively securing N3 allocation for next-generation AI deployments, TSMC’s 3nm production capacity is projected to operate at its limit through 2026. Beyond NVIDIA’s Vera Rubin platform, primary competitors and hyperscalers are migrating their proprietary silicon to the 3nm standard. AMD’s MI350 series accelerators, Google’s TPU v7 (Ironwood) infrastructure, and Meta’s proprietary MTIA-v3 inference chips are all slated for N3 production through the 2026 and 2027 fiscal cycles. This complete capacity absorption effectively neutralizes near-term cyclicality risks, granting TSMC significant pricing leverage and the ability to command premium margins for expedited orders.
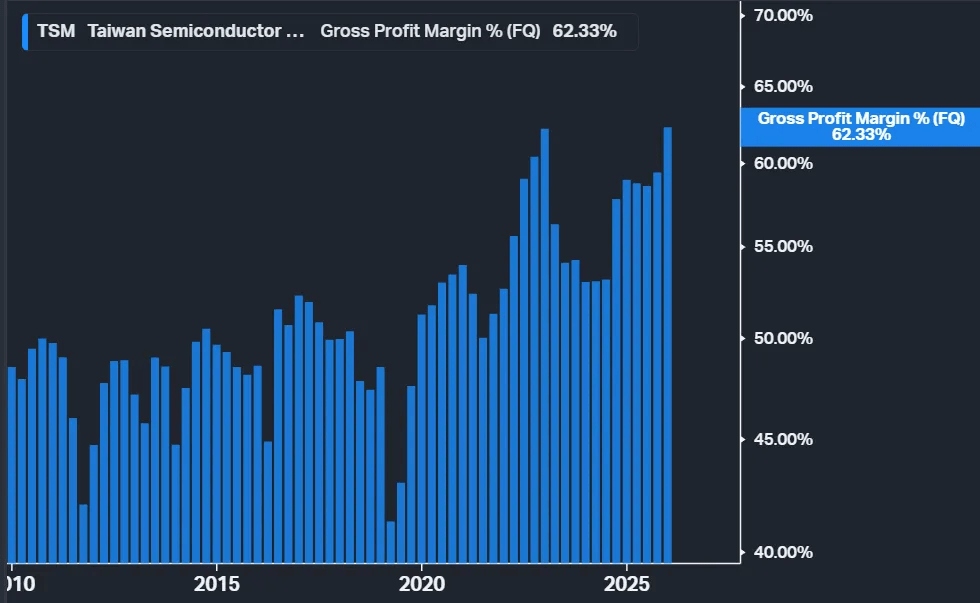
TSMC Gross margin expanded significantly in 2025. Source: Koyfin
TSMC’s near-monopoly in advanced packaging represents one of the most durable economic moats. Through its proprietary Chip-on-Wafer-on-Substrate (CoWoS) and System-on-Integrated-Chips (SoIC) technologies, TSMC controls the critical production bottleneck, where high-density logic dies are bridged with high-bandwidth memory (HBM).
“Today’s, technology is so complicated. So once you want to design a very, complete or advanced technology, it takes two or three years to fully utilize that technology.”
C. C. Wei – TSMC Chairman and CEO, (4Q25 Earnings call)
While competitors attempt to scale alternative packaging solutions, TSMC’s superior yield rates and established integration frameworks grant the foundry unprecedented pricing leverage.
Source” SLP Alpha Research
Memory – HBM is critical component and is in deep deficit, windfall profits for oligopoly
High Bandwidth Memory (HBM) has emerged as the structural bottleneck for Vera Rubin production. The global supply of these advanced memory stacks remains constrained. Only three producers currently, SK Hynix, Samsung and Micron can produce HBM chips and all are working at maximum capacity. Currently they enjoy an unprecedented pricing power, driving substantial margin expansion while hyperscalers compete for strictly allocated volumes throughout the 2026 and 2027 Capex cycles. Underscoring the magnitude of this demand shock, Micron recently upwardly revised its industry outlook, forecasting a 40% compound annual growth rate that will propel the HBM TAM from roughly $35 billion in 2025 to $100 billion by 2028—achieving this milestone two full years earlier than prior models indicated. This rapid expansion signals that HBM became highly inelastic, premium-priced product.
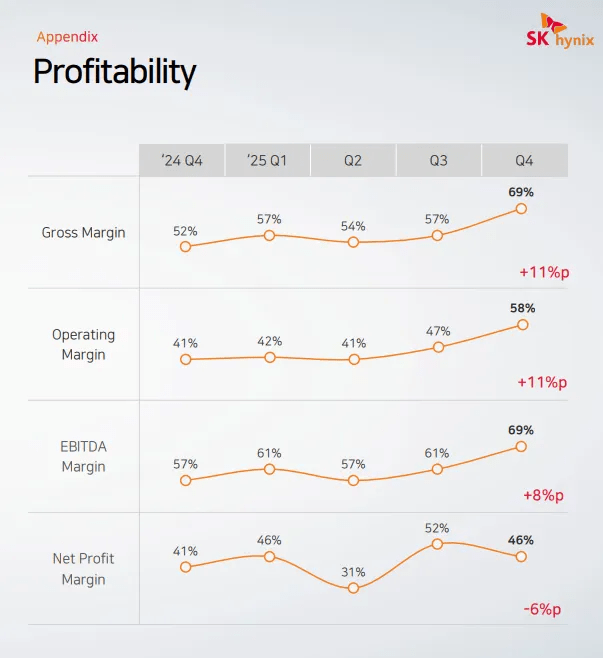
Source: SK Hynix
The supply squeeze is reflected in Micron’s numbers. In the latest quarter revenue grew by 196% yoy and gross margin reached 74% from 37% year earlier.
Source: SLP Alpha Research
“We expect both DRAM and NAND industry bit demand in calendar 2026 to be constrained by supply. We continue to expect supply-demand conditions for both DRAM and NAND to remain tight beyond calendar 2026”
“prices increased in the mid-60s percentage range, driven by tight industry conditions”
Micron, 2Q26 Results
Testing – another bottleneck, driving revenue growth and profitability for suppliers
Vera Rubin architecture poses challenge to semiconductor testing providers, fundamentally driven by the physical complexity of TSMC’s CoWoS packaging and the introduction of HBM4. Because these multi-die, heterogeneous configurations require rigorous defect inspection and high-power thermal burn-in protocols to ensure yield integrity, the Rubin GPU necessitates a significant increase in total testing time per unit compared to preceding architectures. This extended diagnostic duration reduces aggregate throughput across existing testing facilities, creating a supply-demand imbalance. Consequently, this dynamic benefits Automated Test Equipment (ATE) providers, increasing order volume and prices.
Teradyne plan to double the revenue on the back of AI boom. Source: Teradyne
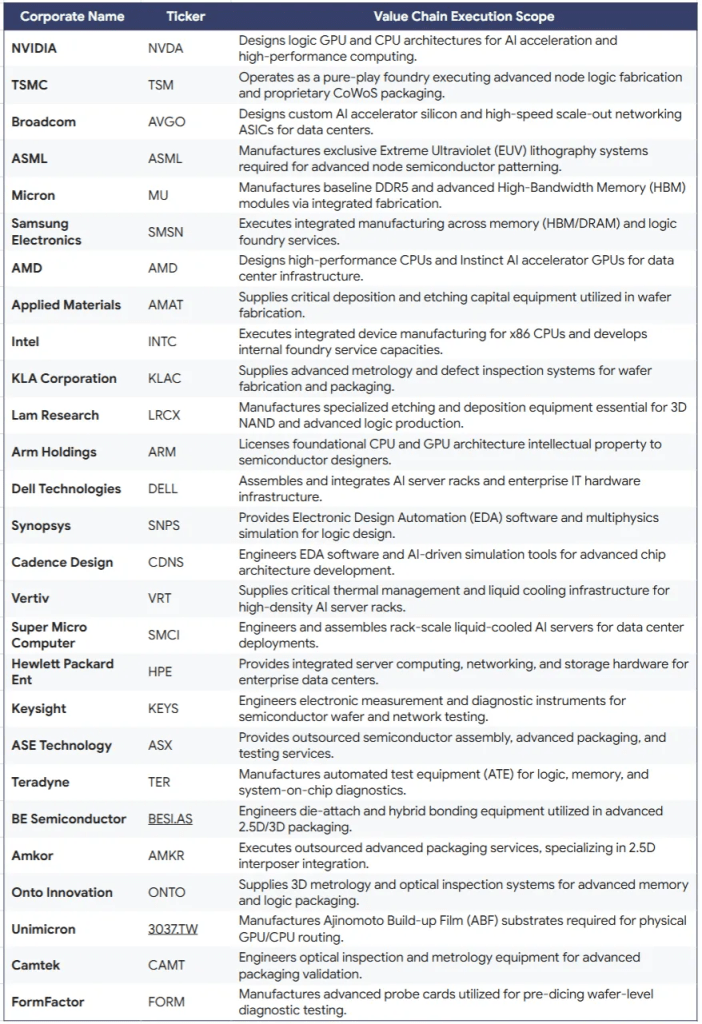
Companies in the semiconductor value chain
The following companies benefit from structural supply-demand imbalances, elevated capital intensity, and resulting pricing leverage observed across the AI hardware sector